

Why Firefox pdf reader can't find or copy russian symbols across file?
So, I try to migrate from Chrome. I open pdf in Chrome, select some text "альтаир" and now I have exactly "альтаир" in buffer (clipboard). Then find "альтаир". So ok, I finded all "альтаир". I open pdf in Firefox, select some text "альтаир" and there is problem with coding Î ̧Ú‡Ë . So, of course, if I write "альтаир" in find window - it will not work. WAIDW ? Thanks!
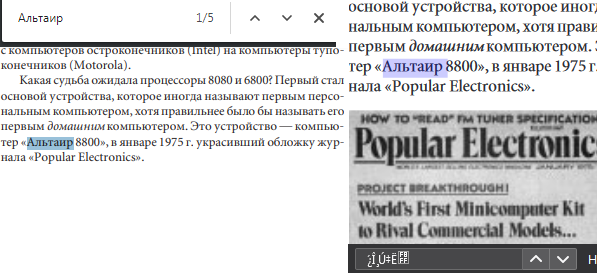
Chosen solution
Hopefully that doesn't affect very many documents. Not sure there's any way of knowing.
Read this answer in context 👍 1All Replies (6)
Hi Orbb, can you share a link to a PDF that has this problem?
Note: This forum diverts posts containing a URL to a link moderation queue, so it's normal that there is a delay of several minutes before your reply appears if you include a URL.
jscher2000 said
Hi Orbb, can you share a link to a PDF that has this problem? Note: This forum diverts posts containing a URL to a link moderation queue, so it's normal that there is a delay of several minutes before your reply appears if you include a URL.
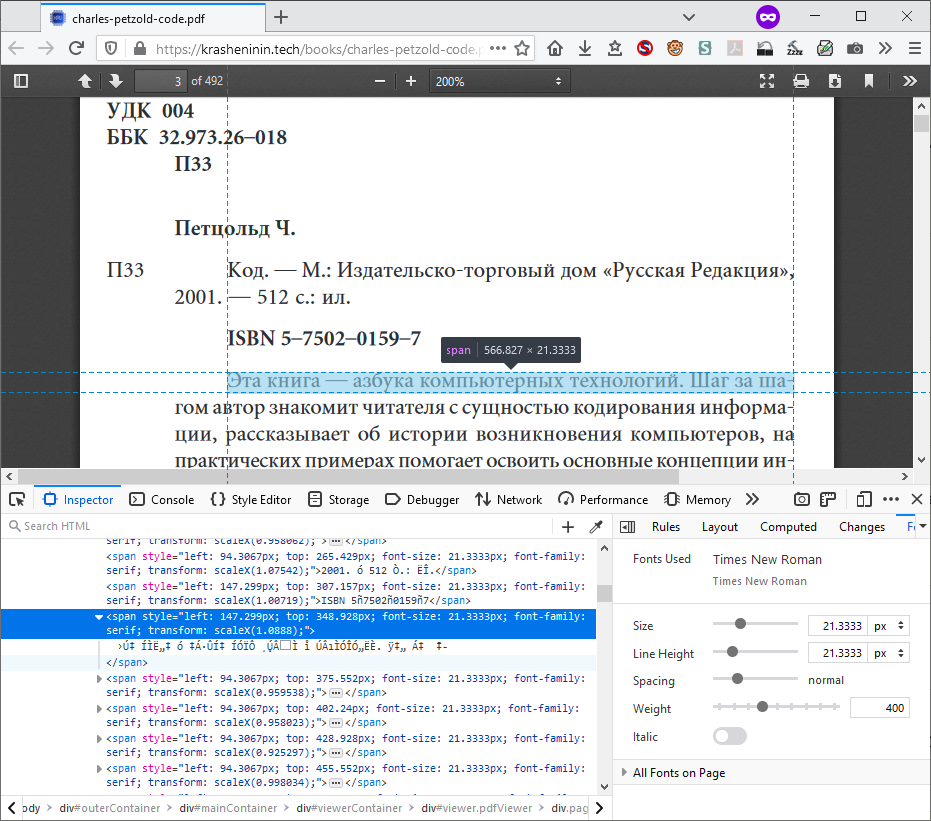
https://krasheninin.tech/books/charles-petzold-code.pdf
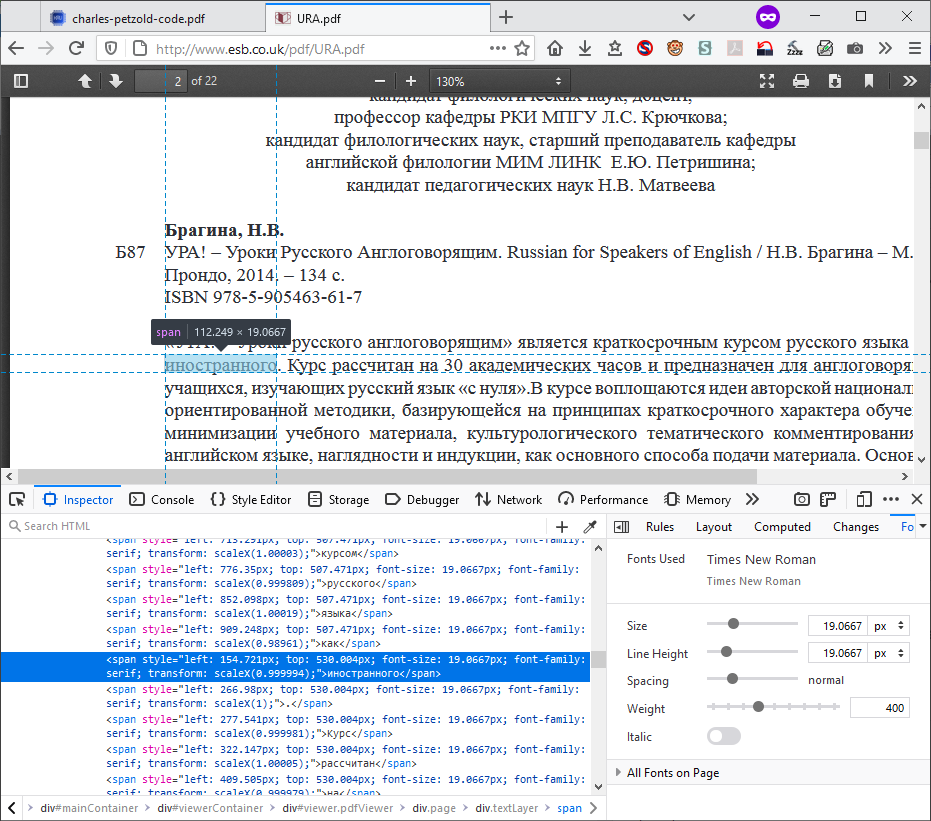
I am attaching comparison screenshots between that PDF and another one that popped up in a search. This shows the HTML of the transparent text layer used for searching and selection (and the nonsense characters).
I suspect the problem in your example is that the document that was converted to PDF did not use Unicode encoding but instead used one of the older methods of character substitution that were common before Unicode became standardized and widespread. But I haven't dug into the PDF in detail.
When you are viewing a web page, Firefox allows changing among character encodings to see which one works best, but this isn't an option for PDFs (grayed out).
You could test the latest version of the PDF.js viewer by saving that PDF and loading it into the web app version here:
https://mozilla.github.io/pdf.js/web/viewer.html
(Look for the file folder icon on the viewer's toolbar.)
If the same problem occurs, then this bug probably needs to be fixed "upstream" in the PDF.js project. You can submit an issue here:
https://github.com/mozilla/pdf.js/issues/
If the problem does not occur in the web app version then either a bug fix will arrive in Firefox eventually, or there is a separate bug in how the viewer is implemented in Firefox.
Modified by jscher2000 - Support Volunteer
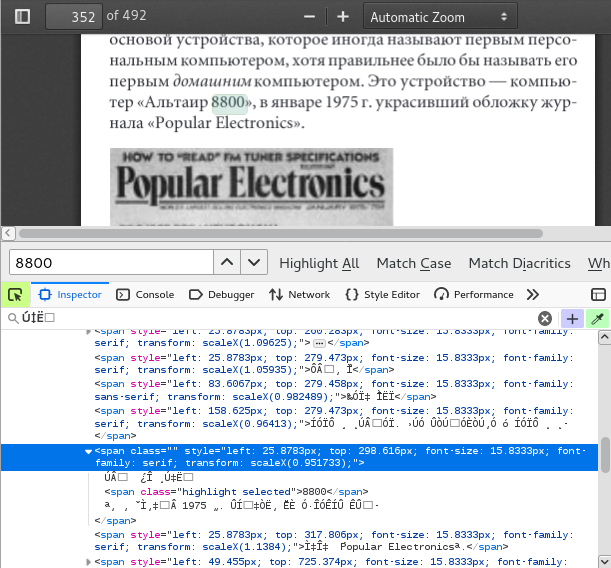
Yes, it doesn't find the 'Altair' text, but I can find the '8800' text.
jscher2000 said
the document that was converted to PDF did not use Unicode encoding
But Chrome can handle such bad files. That's why I thought I was doing something wrong.
jscher2000 said
You could test the latest version of the PDF.js viewer by saving that PDF and loading it into the web app version here: https://mozilla.github.io/pdf.js/web/viewer.html
I can, but the result is the same obviously. Thus, if I correctly understood, the short answer is "it just doesn't work" . Thank you for you time!
Chosen Solution
Hopefully that doesn't affect very many documents. Not sure there's any way of knowing.