

PDFs used to save automatically to downloads, now it prompts me every time
Hey there,
I use Adobe Acrobat Pro to open PDFs for work. It always worked fine, set up to automatically open PDFs in Adobe, and they save to Downloads folder. For some reason now, after an update, the PDF always pulls up a save box and asks me to name the file (significantly slows down workflow). This only happened after an update.
I've figured out that the issue is related to a way that the PDFs are generated. So if I click it via a link that ends in .html instead of .pdf, it assumes it's a webpage and opens the pdf link in browser, and from there I have to click save, and then I'm prompted to type in the file name.
If I open a PDF link that's an actual .pdf file URL, then it saves to Downloads automatically and names the file "contractfile-1111" or whatever, numbered consecutively. Any ideas on how to get around this?
Thanks
Alle Antworten (7)
Hi Peter,
We can try to look into your 'Files and Applications' configuration under Firefox settings. Make sure to save your files to 'Downloads', and set 'PDF' downloads to be automatically saved as a file. You can look into my uploaded screenshot of the optimal settings for your scenario.
Please let me know if you still have any issues on this topic.
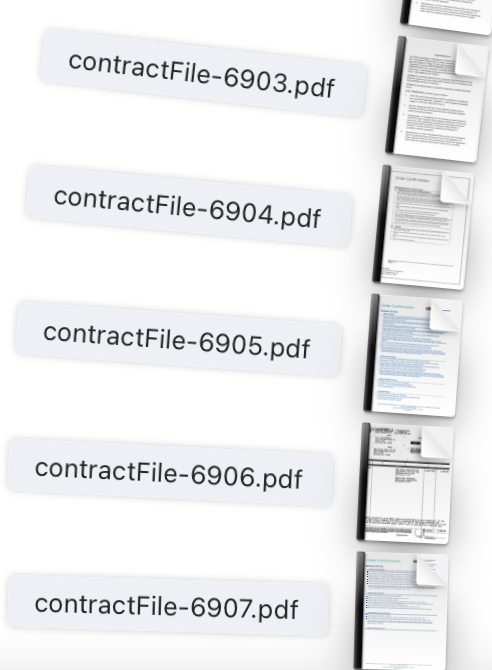
Yeah, this is all set. It's hard to explain the issue exactly. I want it to open automatically in Adobe Acrobat, and for most PDF links it does do that automatically - it saves the file to my downloads folder, naming it automatically as the next number contract file (see first screenshot), and opens immediately.
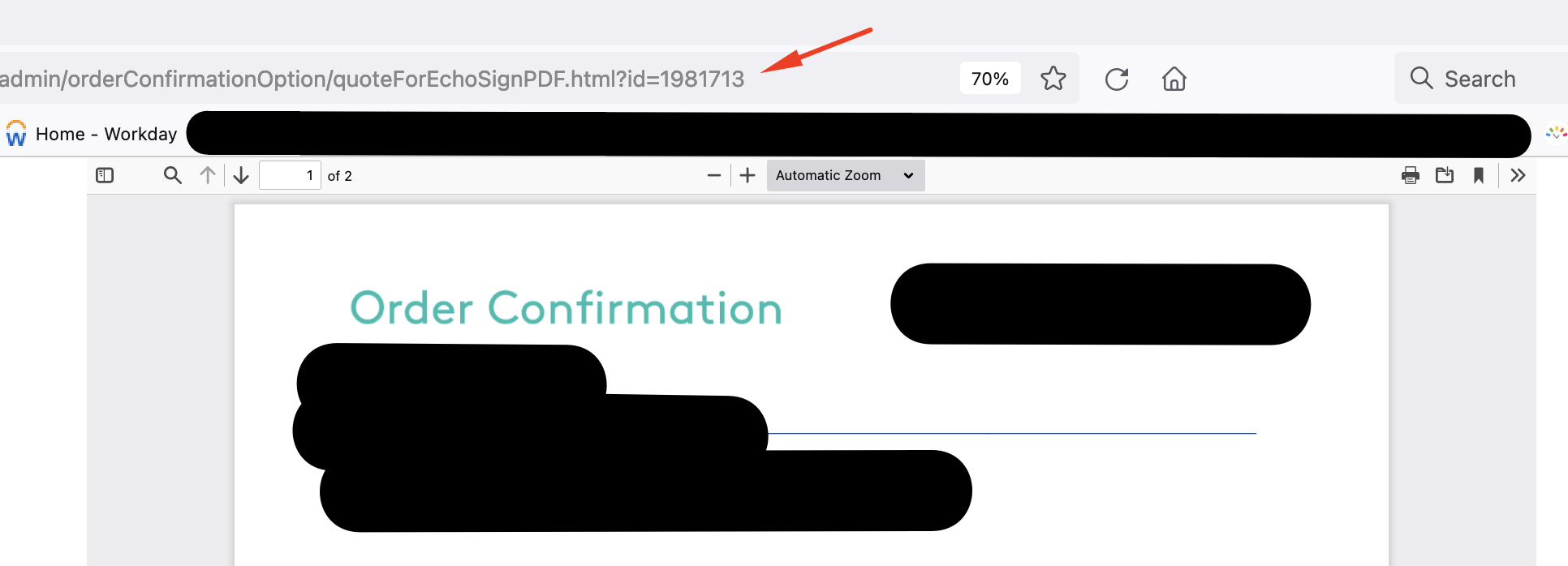
But for a certain type of PDF link, it by default does not read it as a pdf file, but rather a URL (I think), and so it opens that in Firefox PDF viewer. (second screenshot).
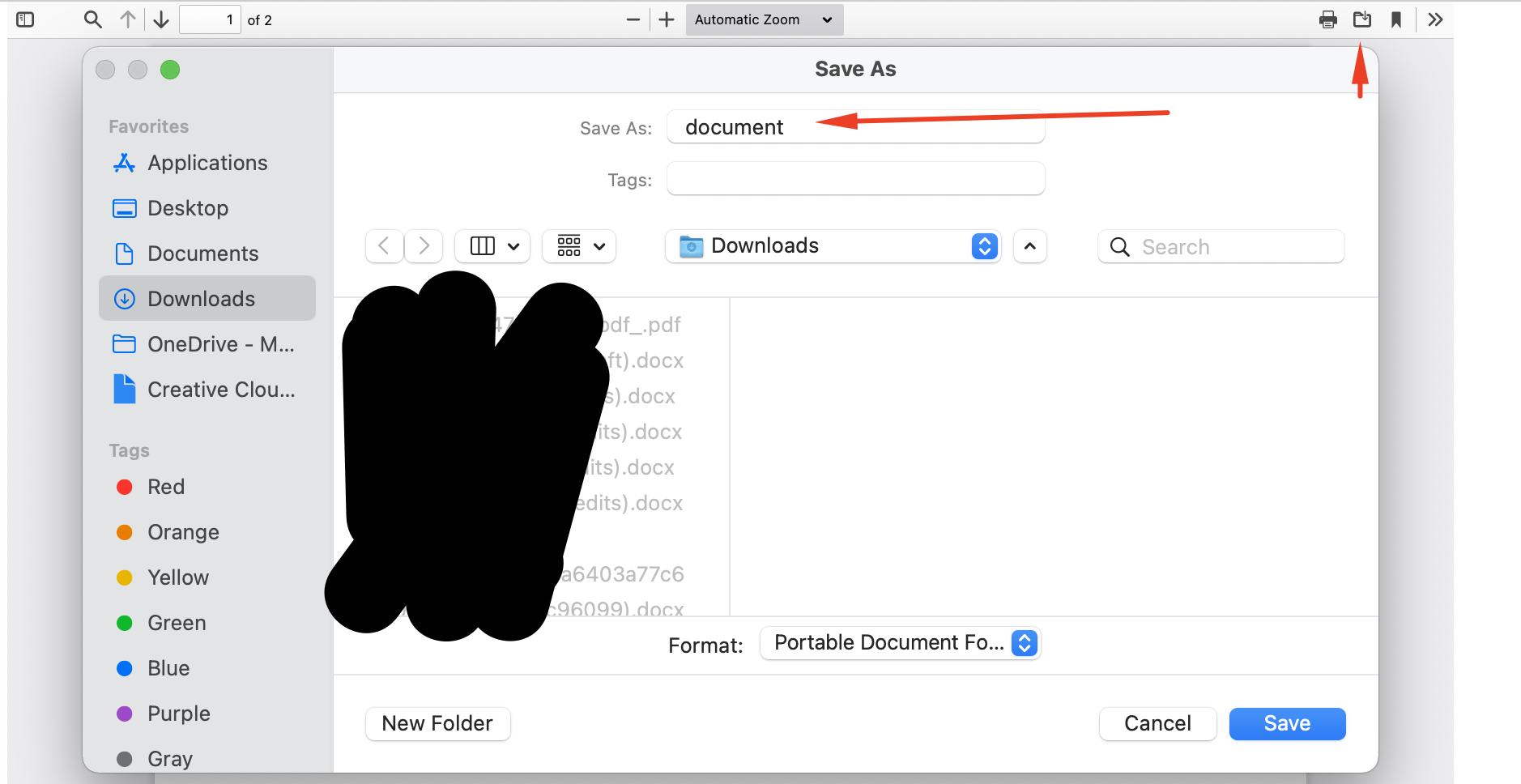
From there, I then need to click download file, but then the save window pops up asking me what I want to name it, so it won't load automatically in Adobe and I have to name it something new every time. (third screenshot).
.....
Geändert am von chincsx123
.....
Geändert am von chincsx123
Looking at your screenshot, the HTML link contains an embedded PDF. Hence causing the issue. Since you are using macOS, give this Linux command a try.
1. Open up your terminal 2. Run this command >>> wget -r -A.pdf <your html link here>
Example: wget -r -A.pdf https://mozilla.github.io/pdf.js/web/viewer.html
Geändert am von malaysia.airlines.journal
What would that do in the long run though? The URL is different every time, so is it going to fix the core issue?
Hi peter.wolkow, jscher offers an explanation in this thread which might be relevant -
Download of pdf attachments https://support.mozilla.org/en-US/questions/1381850