

Problem moving to the next page of data within a web page
Some web pages contain data split into pages and provide something like "Previous 1 2 3 4 5 6 7 Next" at the bottom of each page. One example is https://support.mozilla.org/en-US/products/firefox?as=u&utm_source=inproduct#search I would like to be able to move between pages without using the mouse using a keyboard shortcut.
Is there any way that Firefox could simulate a mouse click on a particular element and link this to a key?
Chosen solution
After some research, I discovered the Firefox network monitor has a Copy as cURL option. With this I can get the data for a page using curl. Since the XHR request does have a page=## parameter, I have written a program to issue the curl commands for all the pages I want. I have also written a program to convert the set of HTML files to a CSV file. Problem solved! I am posting this here in case anyone else has a similar problem.
Read this answer in context 👍 1All Replies (7)
Most pages modify the URL and add a page=## GET parameter, so you can check the location bar to verify this.
You can search the Add-ons website for a suitable next page extension.
The web page that I have a problem with is: https://www.trustnet.com/fund/price-performance/t/investment-trusts?
A previous version of this page did have a page=## parameter, then it changed so that pressing page down many times would load all the data. It has changed again so that it presents pages of 25 funds. The URL does not change when moving between pages and save page as HTML produces the same result for every page (which does not contain the fund data).
I tried searching the Add-ons website, but it said "993 extensions found for "next page". I tried a few of them but without success. Can anyone suggest an extension that will work for this site?
What I am trying to do is get all the data into a spreadsheet. I can do it manually by selecting all the text on each page, pasting it into a text file then running a simple program to produce a csv file. I could automate this if I had a keyboard shortcut for "next page".
It is possible that the page uses XHR to update the content of the current page. You should be able to see these requests in the Network Monitor and maybe also in the Web Console. You can possibly filter only for XHR.
Here is the result of starting the network monitor after loading the page, just showing what happens when ">" is pressed 3 times, showing the request details for the third one.
https://user-media-prod-cdn.itsre-sumo.mozilla.net/uploads/images/2022-08-26-07-09-03-a4ebe6.png
{kind=link}
Note that it is now on page 4, but the request contained "Page": ["3","0"]. I don't know how to interpret any of this information.
Incidentally, how do you screenshot the developer tools (I used alt-printscreen)? Also, how do you get the screenshot image to appear in the middle of the text?
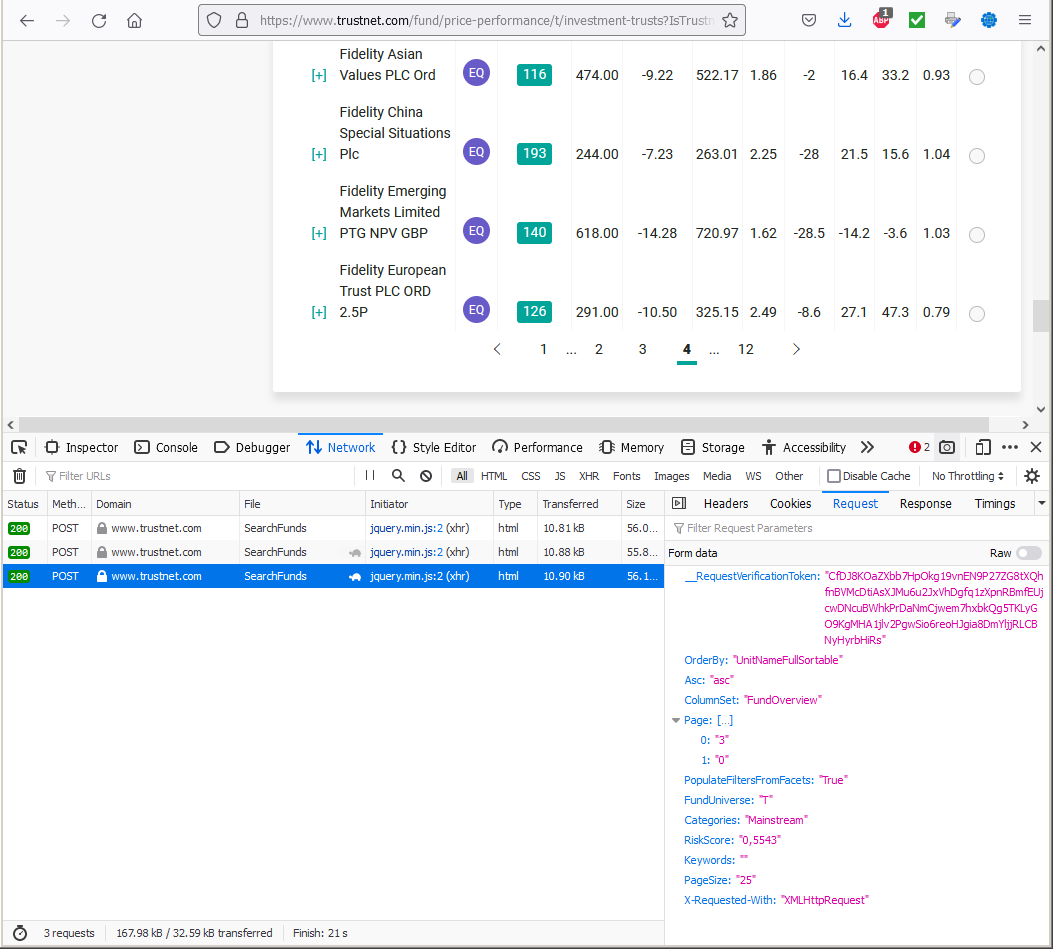
Modified by paul921
I'm still looking for a solution to this problem. The only extension I've found which can move to the next page within this web page is iMacros. Unfortunately the free version of iMacros won't save the data. Can anyone suggest a solution?
Chosen Solution
After some research, I discovered the Firefox network monitor has a Copy as cURL option. With this I can get the data for a page using curl. Since the XHR request does have a page=## parameter, I have written a program to issue the curl commands for all the pages I want. I have also written a program to convert the set of HTML files to a CSV file. Problem solved! I am posting this here in case anyone else has a similar problem.
Note that the Windows command prompt limits the length of a command to 4096 characters, so if the result of Copy as cURL is too big it will be truncated when pasted into the command prompt window. This can be overcome by reading the clipboard within the program which issues the curl commands.